实现背景
假设要做openAI的大模型API封装,可以使用Spring WebFlux提供服务,利用其非阻塞、响应式编程模型来高效处理异步请求。
为什么要做API封装?
- 保护模型:避免直接暴露模型,保护模型的安全性。
- 降低耦合:将模型与业务逻辑分离,降低耦合度。
- 与原有的系统对接:将模型封装成API,方便与其他系统对接。
实现思路
以下是一个基于 Spring WebFlux 封装 OpenAI API 的完整实现例子,使用 Gradle 管理,项目目录结构为 vo、client 和 biz。
项目目录结构
1 | src |
配置 WebClient 类 (client/WebClientConfig.java)
WebClientConfig 用于配置 WebClient,这个类将负责与 OpenAI API 的连接。
业务逻辑 (biz/OpenAIService.java)
OpenAIService 类用于封装调用 OpenAI API 的逻辑,并且通过 WebClient 处理流式响应,返回 Flux<String>。
数据传输对象 (DTO) (vo/PromptRequest.java 和 vo/CompletionResponse.java)
PromptRequest.java:定义发送给 OpenAI API 的请求体数据结构。
CompletionResponse.java:定义从 OpenAI API 接收到的响应数据结构
数据传输对象
响应的数据结构
1 |
|
private List<Choice> choices; 在CompletionResponse类中扮演以下几个重要角色:
- 表示响应中的数据结构:
- choices 字段表示 OpenAI API 响应中的一个重要部分。根据 OpenAI API 的响应格式,生成的文本是以 choices 的形式返回的,每一个 Choice 对象包含一段生成的文本。
- 封装多个 Choice 对象:
- 由于 OpenAI API 可以生成多个结果(多个选择),因此需要用 List
来封装这些生成的结果。List 是一个集合类,允许存储多个 Choice 对象,每个对象代表一个生成的文本。
- 将 JSON 映射为 Java 对象:
- 当 OpenAI API 返回一个包含 choices 的 JSON 数组时,Spring WebFlux 的 WebClient 会将 JSON 映射为 Java 对象。List
对应的是 JSON 中的数组,Choice 类中的 text 字段对应 JSON 中每个选项的文本内容。
假设 OpenAI API 的响应如下:
1 | Copy code |
根据这个 JSON 结构:
choices 是一个数组(List),每个数组元素对应一个 Choice 对象。
Choice 对象中有一个 text 字段,存储生成的文本。
private List<Choice> choices; 在这里就是用来存储和处理这个数组,代表生成的多个文本结果。
在程序中的作用
当调用 OpenAI 的 API 并接收响应时,Spring 的反序列化机制会将 JSON 数据自动映射到 CompletionResponse 中。choices 字段将包含多个生成的文本,每个文本存储在一个 Choice 对象中。
可以通过以下方式访问生成的文本:
1 | CompletionResponse response = ... // 从 API 获取响应 |
这样,就可以逐个处理生成的文本结果。
请求的数据结构
1 | /** |
WebClient 配置
1 |
|
什么是 WebClient?
WebClient 是 Spring WebFlux 提供的一个响应式、非阻塞的 HTTP 客户端,允许应用程序与外部服务进行交互。相比于传统的 RestTemplate,WebClient 能更好地支持异步操作,特别适合处理高并发、低延迟的应用场景。
WebClient 允许我们以编程的方式发起 HTTP 请求并处理响应。可以发送 GET、POST、PUT、DELETE 等各种 HTTP 请求,且可以处理 JSON、XML 或其他格式的数据。
WebClient 的使用步骤
- 创建
WebClient实例:通过WebClient.Builder创建WebClient实例,可以配置baseUrl、header等信息。 - 发起请求:使用
WebClient实例发起请求,可以发送 GET、POST 等请求。 - 处理响应:通过
retrieve()方法获取响应,可以处理响应数据。
示例
1 | // 创建 WebClient 实例 |
处理响应
1 | response.subscribe(res -> { |
Mono 或 Flux:
Mono 和 Flux 是响应式编程模型中的核心部分,分别表示单个元素(Mono)或多个元素(Flux)的异步序列。
这些序列是“惰性”的,意味着它们不会在定义时立刻执行。只有当你“订阅”它们时,数据才会开始流动,或者说,操作才会被真正执行。
subscribe() 方法:
subscribe() 是触发响应式流的关键操作。当你调用 subscribe(),整个请求流程才会被激活和执行。
subscribe() 的参数是一个 Consumer,表示当有数据发出时,你可以定义如何处理这些数据。在这个例子中,res 就是 HTTP 响应体的结果。
假设和前端进行交互,controller如下
1 |
|
SseEmitter
SseEmitter 是 Spring 提供的一个类,用于处理 Server-Sent Events (SSE),一种服务器端推送技术。
通过 SseEmitter,服务器可以持续向客户端发送事件,而客户端只需要建立一次连接即可接收多个事件。
SSE 是基于 HTTP 协议的持久连接,这使它在实时数据更新场景中非常有用,例如股票价格、社交媒体通知、实时聊天消息等。
服务类 (biz/OpenAIService.java)
- 连接是单向的,服务器推送数据,客户端接收数据。
- 客户端通过
EventSource API来接收服务器推送的事件。
1 |
|
其他的组件如何调用这个服务类?
1 | package com.example.anothercomponent; |
更为简答的实现方式,不需要显式订阅
直接返回ServerSentEvent<String>对象,Spring MVC 会自动将这个对象转换为 SSE 响应。
1 |
|
前端如何使用
1 | const eventSource = new EventSource('/api/openai/generate'); |
SseEmitter对象
SseEmitter 是 Spring 提供的一个类,用于处理 Server-Sent Events (SSE),一种服务器端推送技术。通过 SseEmitter,服务器可以持续向客户端发送事件,而客户端只需要建立一次连接即可接收多个事件。
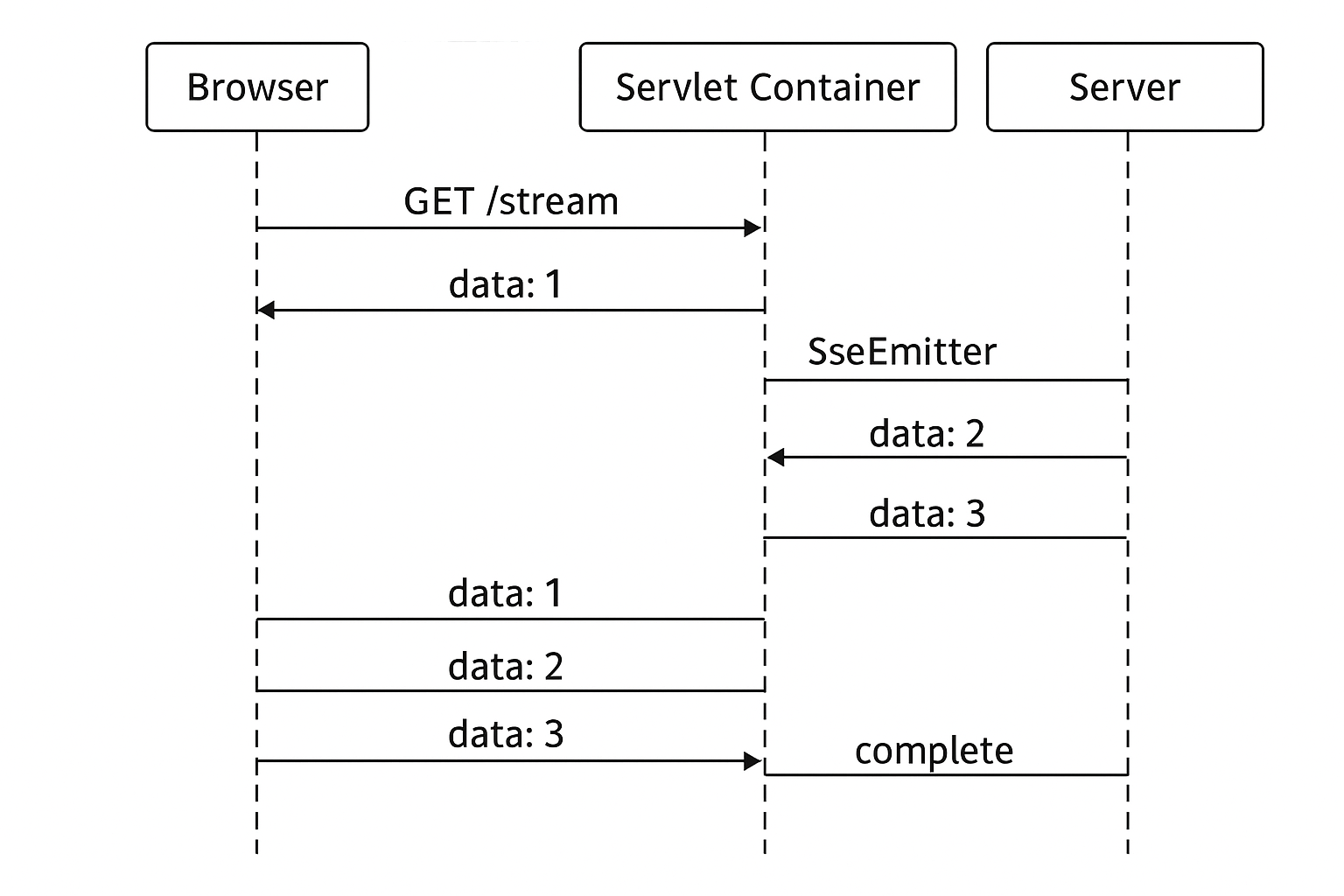
在 Java 里,SseEmitter(Spring MVC 提供的 SSE 对象)之所以能流式返回,本质上是利用了 HTTP 长连接 + 分块传输(Chunked Transfer Encoding) 来实现的。
我给你拆开解释一下原理:
1. SSE 是什么
- SSE(Server-Sent Events)就是浏览器向服务器发起一个 HTTP 请求,
- 服务器不立刻关闭连接,而是不断 分批发送数据 给浏览器。
- 客户端(通常是浏览器
EventSource)会不断接收这些数据并触发事件。
SSE 是单向的(服务器 → 客户端),不像 WebSocket 那样双向通信。
2. SseEmitter 的实现原理
Spring 通过 SseEmitter 让你轻松用 Java 写 SSE 服务。
关键点:
-
底层用的是 Servlet 异步处理(
AsyncContext) -
HTTP 头里会返回:
1
2
3Content-Type: text/event-stream
Cache-Control: no-cache
Transfer-Encoding: chunked -
Transfer-Encoding: chunked让服务器可以分段写数据到 TCP 流,而不用等到一次性写完。 -
每次你调用:
1
emitter.send(SseEmitter.event().data("hello"));
Spring 会:
- 把
"data: hello\n\n"格式的数据写入响应流(OutputStream或Writer) - 不关闭响应流
- 立即
flush(),让客户端立刻收到这一段数据
- 把
-
连接保持打开状态,直到:
- 你调用
emitter.complete()(手动结束) - 或超时/异常
- 你调用
3. 流式的关键:不关闭 & 立即 flush
传统的 HTTP 响应是:
- 服务器生成完整内容
- 一次性写入响应流
- 关闭连接
SSE 则是:
- 打开连接(HTTP 长连接)
- 写一部分数据(
flush立即发出) - 等待一段时间,再写下一部分数据
- 重复,直到结束
4. 一个例子
1 |
|
客户端:
1 | const es = new EventSource("/stream"); |